Engineering Privacy and PII Protection From the Get Go
Let’s play an imagination game to begin to better understand the power of personally identifiable user data. This one is for all the burrito lovers out there! What if there was an app that could recommend the perfect burrito for you?
Well, I’m here to espouse the wonders of BurritoMatch!
BurritoMatch is the hottest thing in burrito recommendation engines. It will take into consideration dietary restrictions like pescatarian, vegan, omnivore, halal or kosher.
BurritoMatch will also be able to help you find burritos that are safe for you to eat if you have medical conditions like low carb for diabetes, gluten-free for celiacs, and allergens for people with allergies. Are there any ingredients that you just hate or love like avocado or sour cream?
BurritoMatch will take all of those dietary preferences and feed them into its incredible advanced recommendation algorithm and find you the perfect burrito. Not only is it the perfect burrito it is also the perfect burrito closet to you …after-all time is of the essence when one is hungry and angry. This app is so good at finding burritos that you love you end up using this app two times a week for six months.
But what if you learn that the data of your penchant for extra sour cream and Modelos with every meal, which exceed the weekly doctor-recommended servings, get sold up to health insurance which then raises your health insurance premiums?
Or what if the data from this app gets sold to organizations that then do religious surveillance because of location data and the halal or kosher filters?
Suddenly this fun app becomes less whimsical and more disturbing. While BurritoMatch only exists for this game, apps that seemed innocuous but turned out to be user data nightmares do exist.
An infamous example of this would be the Flashlight app built by Ihandy. In the older generations of the Iphones, the camera light would only turn on for flash photography. Quickly users wanted a feature that allowed the light to stay on as a steady beam to be used as a flashlight which resulted in a proliferation of third-party Flashlight apps on the App Store. According to an analysis conducted by Appthority, it was determined that the Flashlight app had the capabilities to collect information related to location tracking, read calendars, use the camera, and collect numbers that uniquely identified devices with the potential ability to then pass that data on to advertising networks all without user consent. This is a problem because users do care about how their data is handled.
According to the 2022 Consumer Privacy Survey conducted by Cisco of 2600 adults across 12 countries 76% of respondents said “they would not buy from a company who they do not trust with their data”. So not only is this about earning and improving customer trust, this is an issue around respect, given that “81% of respondents agreed that the way an organization treats personal data is indicative of how it views and respects its customers”.
Whatever code you write, impacts people, whether it’s a burrito app, a school rating app, or a healthcare policy app. You want your impact to be positive and you want to build a better product whether that be (a better burrito/a better school/better access to healthcare) that is not loaded with unintended consequences hiding in the code and architecture. Because when Privacy and Security are mishandled the consequences can affect people in very real ways.
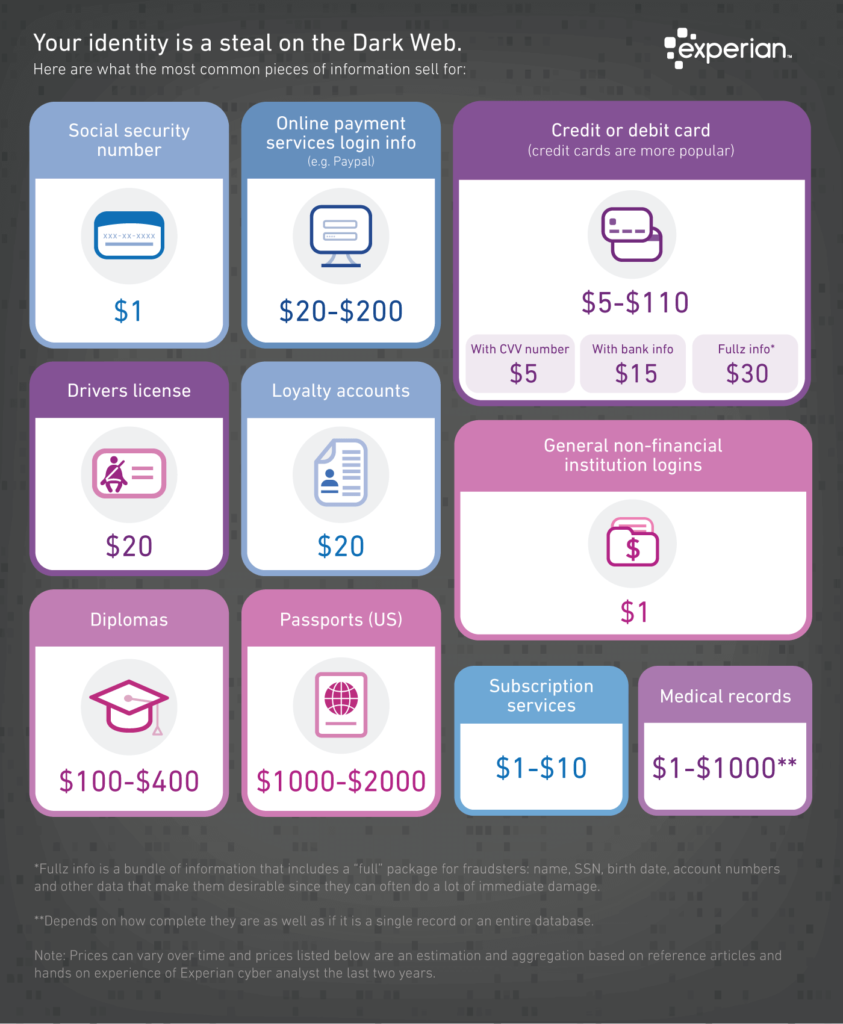
Just take for instance this small example of what identity data is worth on the dark web in this Experian infographic from 2017. Even though this infographic is outdated this demonstrates the real costs associated with identity theft most likely from data breaches and other data mismanagement. Values range from about $1.00 for Social Security numbers to $2,000 for US passports.
When the technology industry speaks about Privacy a lot of buzzwords and rants get thrown around in the media. We also usually hear about it in terms of the damages and how many millions of dollars were lost. At its core, it’s about an individual’s right to maintain control over personal information. Privacy allows people the ability to be themselves and live their lives as they see fit because the individual is the one dictating what information to share, where to share it, and with whom to share it on the internet.
When our industry speaks about Security there are even more buzzwords and rants about phishing, OWASP top 10, hacking, hacking … and more hacking. At its core, Security is the systems and controls we build and implement to protect information. That information varies and can be things like proprietary code, credit card information, and yes personally identified information also referred to as PII.
PII is defined as any information that can be used to identify an individual. There are 2 types of PII, sensitive and non-sensitive. Per the Department of Homeland Security “sensitive PII is data that, if lost, compromised, or disclosed without authorization, could result in substantial harm, embarrassment, inconvenience, or unfairness to an individual”.
The important bit of information that defines sensitive PII is any data that can both quickly and accurately identify an individual. Examples of sensitive PII are social security numbers, Driver’s license numbers, or biometrics data. Some industries will use the term strong identifier instead of sensitive PII.
Non-sensitive PII is personal information that on its own cannot be used to quickly and accurately identify an individual. Non-sensitive PII also known as weak identifiers is information that is generally not considered to be a risk to an individual’s privacy or security if it is lost, compromised, or disclosed without authorization. For example, a home address might not be used to quickly and accurately identify an individual because maybe they live in a large apartment complex.
Care must still be used with non-sensitive PII because it can become sensitive. An example of this would be if you had an address, a birthday, and a gender. With this level of information, you may be able to go back to that apartment complex and quickly and accurately identify that individual.
Listed below are some general examples of these different types of non-sensitive PII. This is not an exhaustive list. This list may not be accurate depending on what countries, industries, or data laws you will be subject to so classify your data with care.
Name
Email address
Phone number
Date of birth
Gender
Address
Zip code
Marital status
Education level
Employment status
Income
Hobbies
Interests
Political affiliation
Religious affiliation
As you can see information like this is commonly collected for purposes such as marketing, customer service, and research. Even though this information is very commonly collected in the United States care is still needed to ensure that this data is protected from unauthorized access, use, disclosure, or destruction.
One way to protect Personally identifiable data is called de-identification.
De-identification is essentially the tools and techniques that organizations use to minimize the privacy of risk using, storing, and publishing data containing PII. Some common techniques used to help de-identify data are:
Redaction: This is the process of removing PII from data altogether. For example, a person’s name and address could be redacted from a document.
Pseudonymization/Masking: This is the process of obscuring PII so that it cannot be easily identified. For example, a person’s Social Security Number could be masked with a series of asterisks.
Generalization: This is the process of combining PII from multiple individuals so that it is no longer possible to identify any individual. For example, a list of names and addresses could be aggregated by city or state or grouping ages together.
Obfuscation: adding noise or distorting the information. For example, you can round off values or replace them with averages. This is a fairly aggressive way to de-identify data and can make it more difficult to use the data but is better for use cases involving sensitive data like health care records.
Protecting PII is more important than ever before because government entities are taking violations seriously and fining companies that they perceive to be mishandling PII and disrespecting consumer data-sharing output requests.
Last year in August 2022, California Attorney General Rob Bonta carried a landmark first enforcement of the California Consumer Privacy Act (CCPA) when makeup and beauty product titan Sephora was fined 1.2 million dollars for failing to disclose to consumers that Sephora was selling personal information and that they failed to process user opt-out requests.
More recently in March 2023, the mental health provider app Betterhelp was fined 7.8 million dollars by the FTC with charges of sharing consumers’ health data, including sensitive information about mental health challenges, for advertising on platforms like Facebook.
“When a person struggling with mental health issues reaches out for help, they do so in a moment of vulnerability and with an expectation that professional counseling services will protect their privacy. Instead, BetterHelp betrayed consumers’ most personal health information for profit. Let this proposed order be a stout reminder that the FTC will prioritize defending Americans’ sensitive data from illegal exploitation.”
When we begin to use PII it is challenging to de-identify correctly because of the tricky and slippery nature of non-sensitive PII. Reverse engineering user identity, also known as re-identification, is still possible from de-identified data sets and our long enough history of data breaches from companies and organizations that we trusted to retain our data like Experian, Target, etc.
There is a famous New Yorker cartoon about a dog. This cartoon states that “On the internet, nobody knows you’re a dog.” However, the truth of it is that you are no longer anonymous any more on the internet. Non-sensitive PII is where some of the hidden dangers of re-identification commonly lie. Our comic panel dog friend can still be re-identified as a dog by using public datasets or that have been made public.
Let’s say that we got access to an anonymized dataset of movies and their rankings from a movie streaming site called Pupflix. In addition to that data set, we also got data from a public movie rating and a ranking site called Squishy To-mahtoes. In both data sets, we found that a user clicked “like” on the doggo documentaries like Lassie, Dog, and the heartwarming Isle of Dogs. This user also clicked “dislike” on the feline features like Cats: The movie, Garfield, and the show The Tiger King. There is no love for Carol Baskin in both the Pupflix and Squishy To-mahtoes data sets.
From using these two datasets, with the six matching movie ratings with a smiler posting and ranking date, we will be able to identify our dog friend. While this example may sound far-fetched, this example is not hypothetical.
This was done by two researchers, Arvind Narayanan and Vitaly Shmatikov at the University of Texas in Austin. On October 2, 2006, Netflix created a public contest called Netflix Prize where they would award 1 million dollars to the person or team that could write a better movie recommendation engine.
To facilitate the work for algorithm improvements, Netflix released a de-identified dataset of 100,490,507 movies from 480,189 subscribers spanning 6 years, between December 1999 to December 2005. Narayan and Shamtikov then were about to use public records from IMDb to match back to the Netflix dataset based on movie, rating, and approximately when the posting happened. Once that happened they were able to find the username in IMDb.
Through their research, they concluded that they only needed 8 movie ratings even with 2 incorrect movie ratings and a posting date that differed by 14 days they were confident that 99% of the users in the Netflix dataset could be uniquely re-identified. Additionally, Narayanan and Shmatikov published that sexual orientation and even political party affiliation could be inferred based on the movie because whether someone liked or disliked a movie is correlated to their worldviews and personal interests.
Another example of re-identification happening from unlikely data sets is the experiment published in 2015 by Dr. Latanya Sweeney, a computer scientist and the founder and director of the Data Privacy Lab at Harvard.
Her experiment showed that one could use newspaper articles to re-identify a patient in anonymized hospital records, 43% of the time. She used patient-level data sets that were available if $50 was paid for usage rights from the state of Washington. The dataset contained information about patients that included patient demographics, clinical diagnoses, procedures, a list of attending physicians, a breakdown of charges, and how the bill was paid for each hospitalization. De-identification of the dataset was attempted by stripping out patient names and addresses but the dataset did often include ZIP codes.
Dr. Sweeney then got a dataset of newspaper stories from a newspaper archive called LexisNexis. She then searched LexisNexis for the term “hospitalization” from stories printed in 2011 in Washington resulting in 66 articles.
Given that newspapers are in the business of informing the public of current events so they did publish specific details like name, age, treatment hospital, and other information that could be matched to the hospital data.
Below is an example of how Ronald Jameson was re-identified after only matching 5 attributes from the newspaper article to the health dataset.
Now that Ronald Jameson has been re-identified we can infer details about his care at Sacred Heart Hospital that is not public data like his treatment costing $71, 708.47 and that his injuries consisted of a fractured pelvis along with pulmonary complications following the accident and surgery.
Due to the work of this study, the state of Washington did make changes to increase the anonymization protocols of the public health records which makes this a feel-good story.
“87% of the U.S. population is uniquely identified by date of birth, gender, postal code”
— Dr. Latanya Sweeney
Some of the real-world examples of people that had their PII misused are the victims of identity theft with their bank accounts drained and their credit scores destroyed. In addition to the human consequences of mishandling user identity data, there are legal challenges and consequences. The first of the modern laws is General Data Protection Regulation (GDPR) which was enacted in 2018. This regulation applies to your organization if any of your users are in Europe. The fines for violations of GDPR are for:
Less severe: up to €10 million, or 2% of the firm’s worldwide annual revenue from the preceding financial year, whichever amount is higher
More severe: up to €20 million, or 4% of the firm’s worldwide annual revenue from the preceding financial year, whichever amount is higher
Here are the acronyms of some of the various privacy laws we do have: CPRA, CCPA, VA CDPA, ColoPA, CT DPA, UCPA, ICDPA, HIPAA, FCRA, FERPA, GLBA, ECPA, COPPA, and VPPA. There are many industry and location-specific privacy laws that companies can be fined or sued for if it mishandles data. Many of the different laws also have different thresholds for when customers need to be notified with public disclosure. Some laws will have a threshold of 100,000 users affected and HIPAA in some states has a threshold of only 250 users affected.
I am not going to go into more specifics since I am not a lawyer. The message here is that there are copious land mines when it comes to violating privacy laws.
In addition to the many laws, this is also a fast-moving and quickly-changing area of tech. There were changes made to the California privacy laws as recently as January 2023 and Colorado has new laws coming online in July 2023.
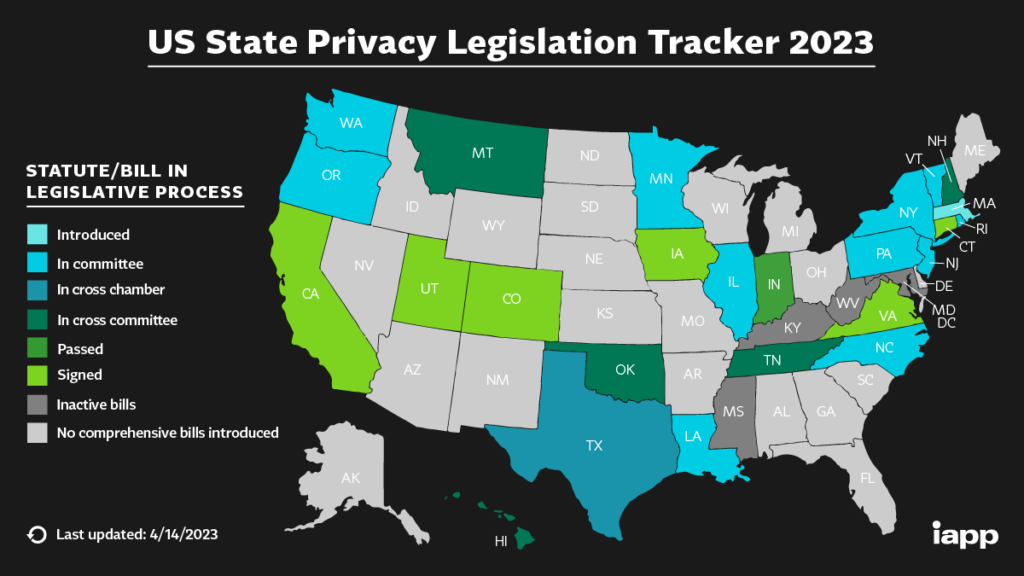
At the time of this writing in the United States there is no comprehensive Federal law that standardizes how PII data should be handled. All the existing laws are patchwork and reliant on individual states to pass and enforce as you can see from the map published by the IAPP.
To wrangle the legal intricacies of these laws I highly recommend that your organization consult a Privacy Lawyer and a Privacy Engineer. It will be easier to adapt to incoming requirements and challenges if there is already a strong well-built foundation of Privacy.
Here are 10 practical things we as engineers can do and advocate for to protect user identity data.
The code that you write has a human impact even if at the surface level it doesn’t seem that way. We as software engineers are the stewards of our user’s data so it’s important to know how users are expecting us to protect their identity because it is the right thing to do even if it takes a little more time and effort to build.
Do not collect or store sensitive data if it’s not needed. If you do nothing else to de-identify or rearchitect how your system processes data, do this. This is by far the cheapest and best way to protect user identity data.
Delete the data you are storing based on a data retention policy. Create a schedule for when that data is going away. This makes it less stressful for those maintaining the system and more cost-efficient. Many cloud storage systems like AWS have configurations to make scheduled data deletion automatic.
Advocate to be incredibly selective of the data that will be processed and stored. Use only the information needed to get the project done. Don’t be afraid to ask if they can get the job done with a smaller data set. Our goal here is to make it more difficult for re-identification attacks to succeed.
For any data that you must keep, store it in a non-personally identifiable way. Ask yourself or your team if you can break up the dataset and store it in multiple systems. Encrypt all that data at REST and transit.
Build in Privacy and Security in the beginning. It is never cheaper, less effort, or faster to bolt it on later. If you try to force it in later you may end up building mission-critical systems that have to be materially changed or retired due to Privacy law violations. When designing the system use the strictest legal and compliance standards to guide your design. For most companies that will be GDPR but some companies will also have to take into account extra laws like companies that process healthcare (HIPAA) or credit card data (PCI).
Do not test with Production data. This is a violation of GDPR and other laws. Depending on what your company policies are you may have to notify the customer that you are using their data in this way which can potentially be embarrassing and impact public perception. Hackers also commonly target dev environments because most of the time we do not harden dev to the same standards as Production. The Dev environment is an inherently unstable environment for features and configurations including Security configurations. If you do need test data sets check out Kaggel or Mockaroo.
Outsource your risk to trusted services if you need to verify things like age instead of storing that in your systems. Companies that do this service as a specialty will build and implement this better than you.
Build apps with good role-based access controls (RBAC). There should be clear permissions between admin roles and user roles. This can help prevent people from stumbling across data they shouldn’t have access to via accidental exposure or something nefarious like an insider threat. If you don’t implement good RBAC what is definitely going to happen is that a summer intern will get access to the admin role in a critical system like your CI/CD system. They will then make a bunch of changes unannounced, either accidentally or on purpose because they don’t know better. This change will then go undetected and fester until the intern leaves. Once they leave everything breaks and you or your team will then have to scramble this Production affecting change.
Make it easy for people a way to opt out of third-party data sharing. When the user chooses to opt out the usability of this software should not be impacted. Also, do not bury the opt out in sub-menus frustrating the user so much so that they give up.
Work with a Privacy lawyer or Privacy engineer. Privacy law is complicated, varied, and quickly changed. For example, if we go back to point #9 about data sharing different states have different laws on how to handle data sharing. As of July 2023, businesses in Colorado must default opt out their users from data sharing whereas in California as of January 2023 “limited use and discourse” is the correct course of action.
After all, I know that you would want the company responsible for your PII to take the utmost care and consideration with your data and do the right thing too.